Last time I benchmarked local models for raw power. This time, for the loop.
A follow-up to my local-model bake-off: which one actually holds up inside a loop-driven coding agent. Real benchmarks, screenshots, and the two places my own measurement was wrong.
A while back, Claude Code and I benchmarked a stack of local models to pick the best one for coding on my Mac Studio: Qwen3-Coder-Next, Qwen3.5-122B, DeepSeek V4, Qwen3.6-27B, and a few others. That round scored raw capability on one-shot tasks, and a flaw in the rubric nearly fooled me before I caught it. Useful work, but it quietly answered the wrong question for what I actually do now.
Because I do not just prompt a model anymore. I run it in a loop. And a model that aces a one-shot prompt can still fall apart in a loop, so I ran a more focused round: scoring the finalists on how they behave inside loop-driven development, not on a single clever answer. The whole thing runs on a Mac Studio in my office. No cloud API, no per-token bill, no code leaving the building. Here is what I found, including the two places my own benchmark was wrong before the models were.
What loop-driven development is
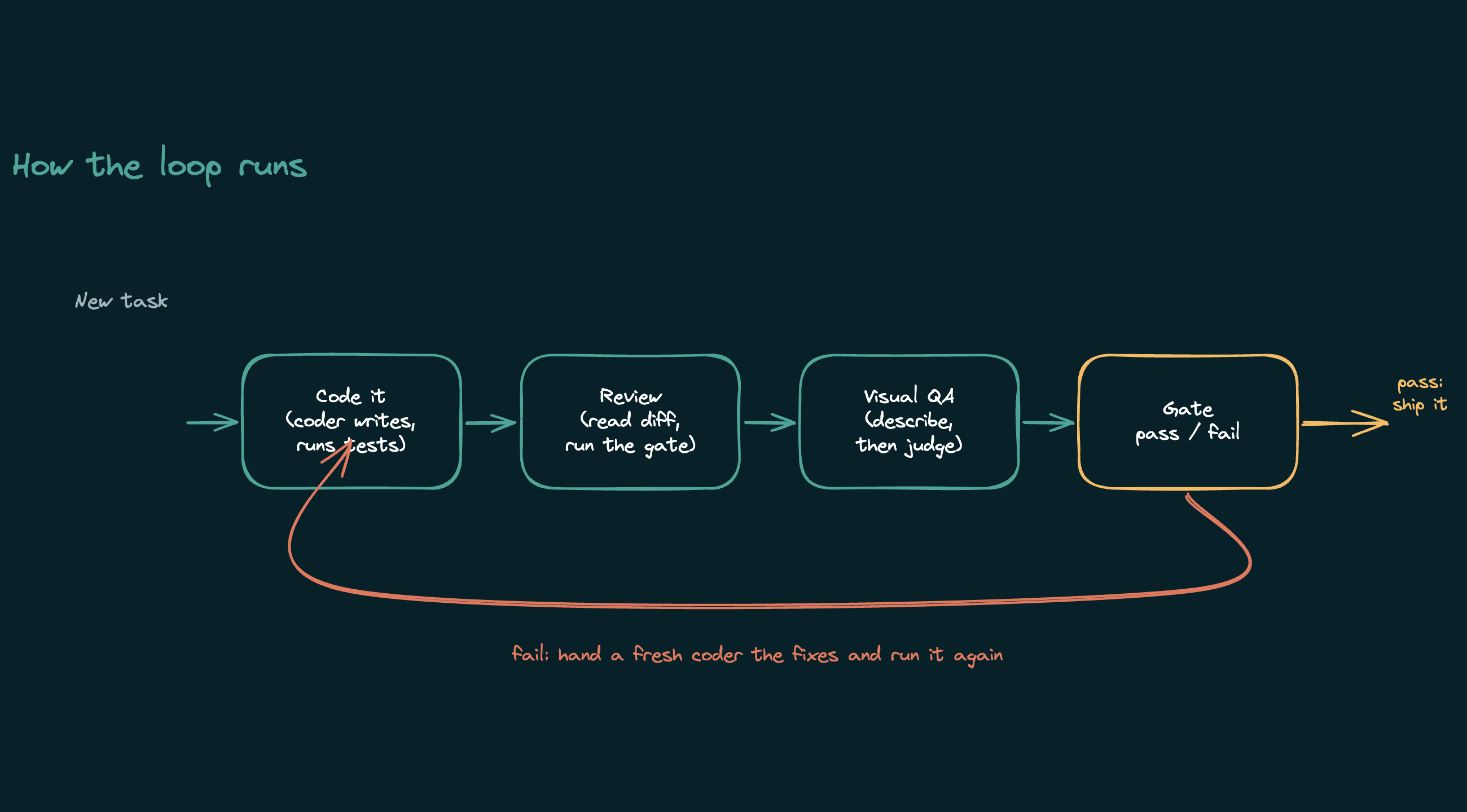
Loop-driven development is the engine behind agentic coding tools like Claude Code and Cursor's agent mode. Instead of prompting a model once and pasting its answer, you put it in a cycle: it reads a task, takes an action with a tool (writes a file, runs a test, takes a screenshot), reads the result, and decides the next move. It keeps going on its own until the work is done or it gives up. One task can be dozens of these turns. Anthropic documents the same pattern in their Agent SDK.
The catch is that the loop punishes things a one-shot test never sees. Slow generation compounds across dozens of calls. Sloppy tool-calling derails the whole chain. A model that rambles burns your token budget on every single turn. So "best local model" and "best local model for the loop" are not the same shortlist, which is the entire reason for this round.
The setup
The shape is one strong generalist plus small specialists, each with a job it cannot fumble. If you want to build a setup like this yourself, I wrote a separate companion guide; this post is about which model to put in it. And if any of the model names are unfamiliar, I keep a plain-English glossary of local-AI terms running.
The two finalists from the earlier bake-off were the ones worth putting in the loop as the coder:
- DeepSeek V4 Flash, run locally through antirez's ds4 engine at an aggressive 2-bit quant. I will call it DS4.
- Qwen3.6-27B, at 8-bit in LM Studio.
The eyes are Qwen3-VL, a 3GB vision model, also in LM Studio. It screenshots the running page and reports what is on it. Everything sits on the same 96GB machine.
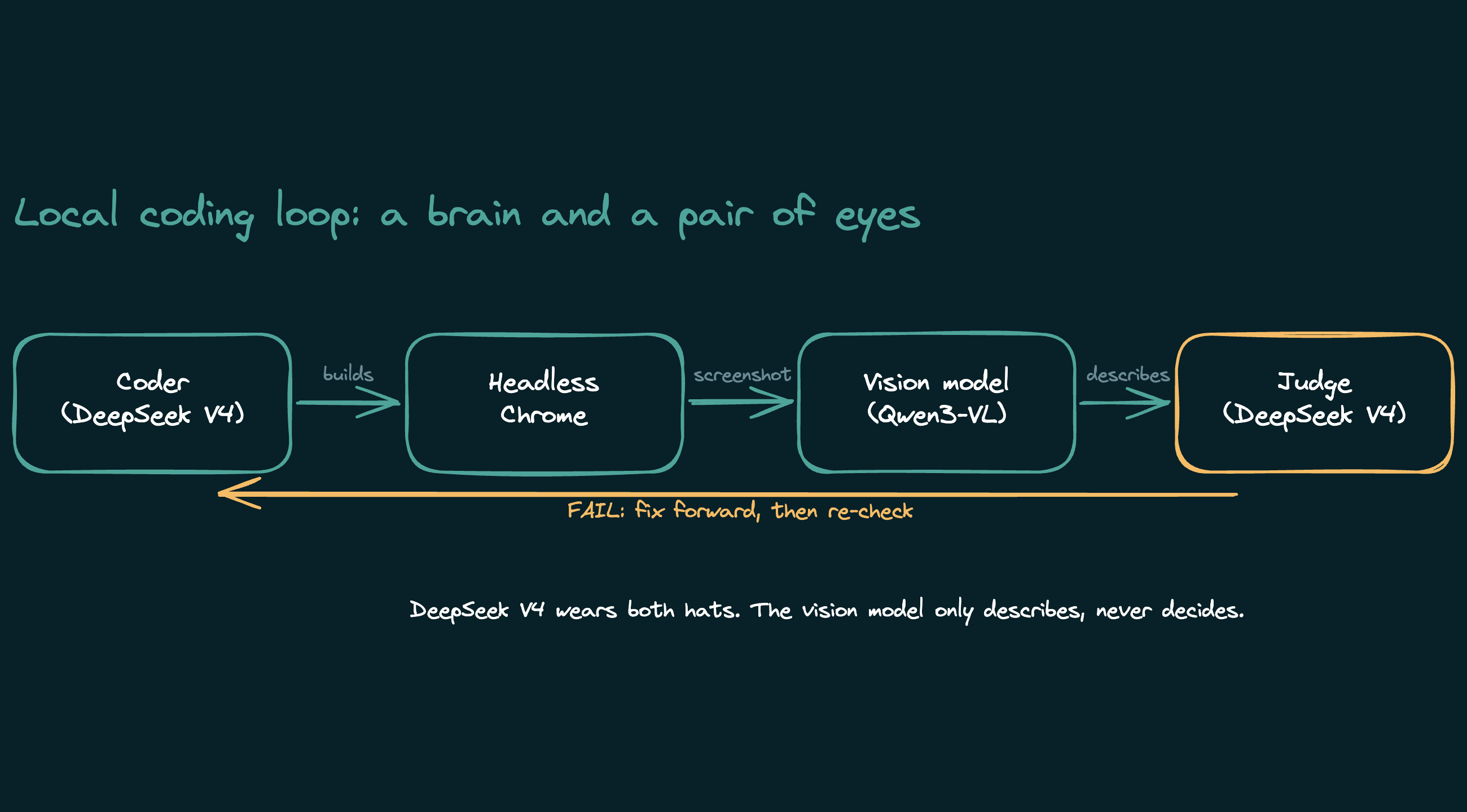
On paper, perfect. In practice the visual QA step failed before I understood why.
Test 1: it could see the bug. It just would not admit it.
I gave it a pricing page where the Enterprise card was shoved off the right edge of the screen.
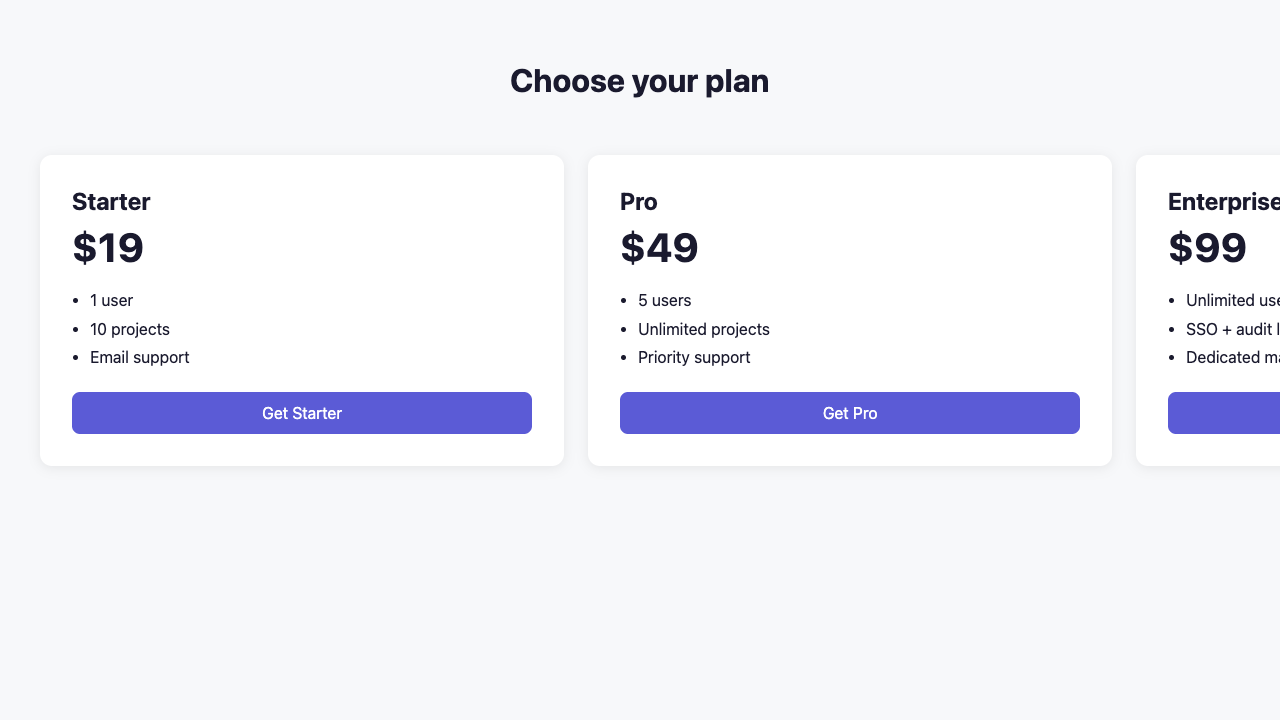
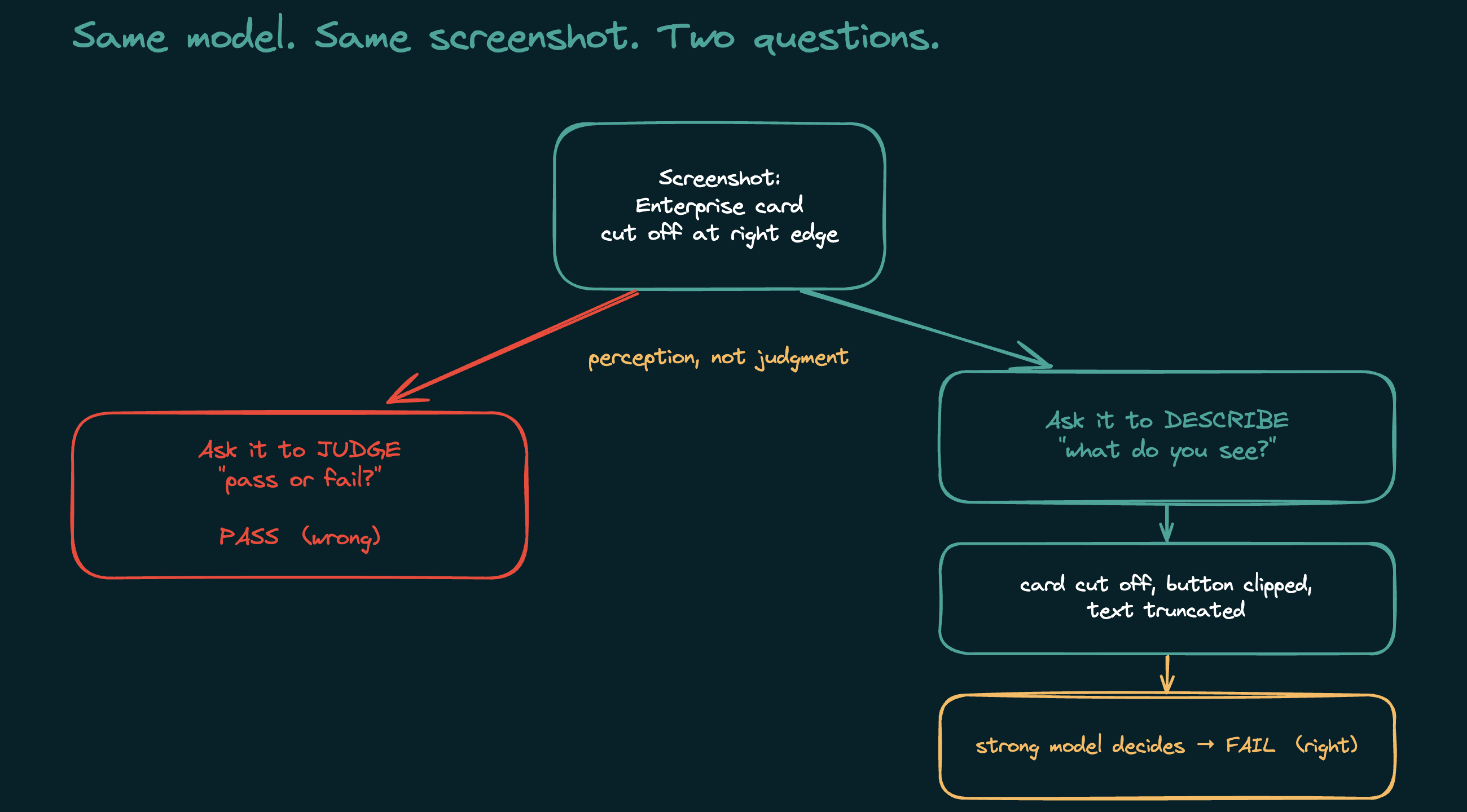
Then I asked the model a simple question: does this match the spec, pass or fail? It said PASS. It wrote that all three cards were fully visible and nothing was cut off.
So I asked it a different question. Not "is this correct," just "describe what you see." And it nailed it: "The Enterprise card is cut off at the right edge. The button is not visible. The text reads 'SSO and audit l' with the rest truncated." Precise and correct, thirty seconds after telling me the page was fine.
That is not a vision problem. It is an approval problem. Ask a small model to grade something and it wants to hand you a good grade. The evaluation framing itself pushes it toward yes.
The fix: describe, then judge
So I stopped asking it to judge. Now the vision model has one job: describe what is on the screen, as plain facts. No verdict. Then a second, stronger model reads that description and makes the call against the spec.
I tested it on the broken page and a fixed version side by side. Broken came back FAIL with the exact reason. Fixed came back PASS. No false approvals either direction.
Test 2: catching what a screenshot can't
A screenshot only sees one thing: a desktop layout, frozen at one moment. So I built a page that looks fine but is broken in two ways a screenshot misses. It throws a JavaScript console error on load, and it uses a table that fits on desktop but cuts in half on a phone.
The old QA looked at the desktop render and passed it. Clean. Then I upgraded the capture, a small Puppeteer script driving headless Chrome: two viewports instead of one, plus the browser's console and network logs. Here is the same comparison table, desktop versus mobile.
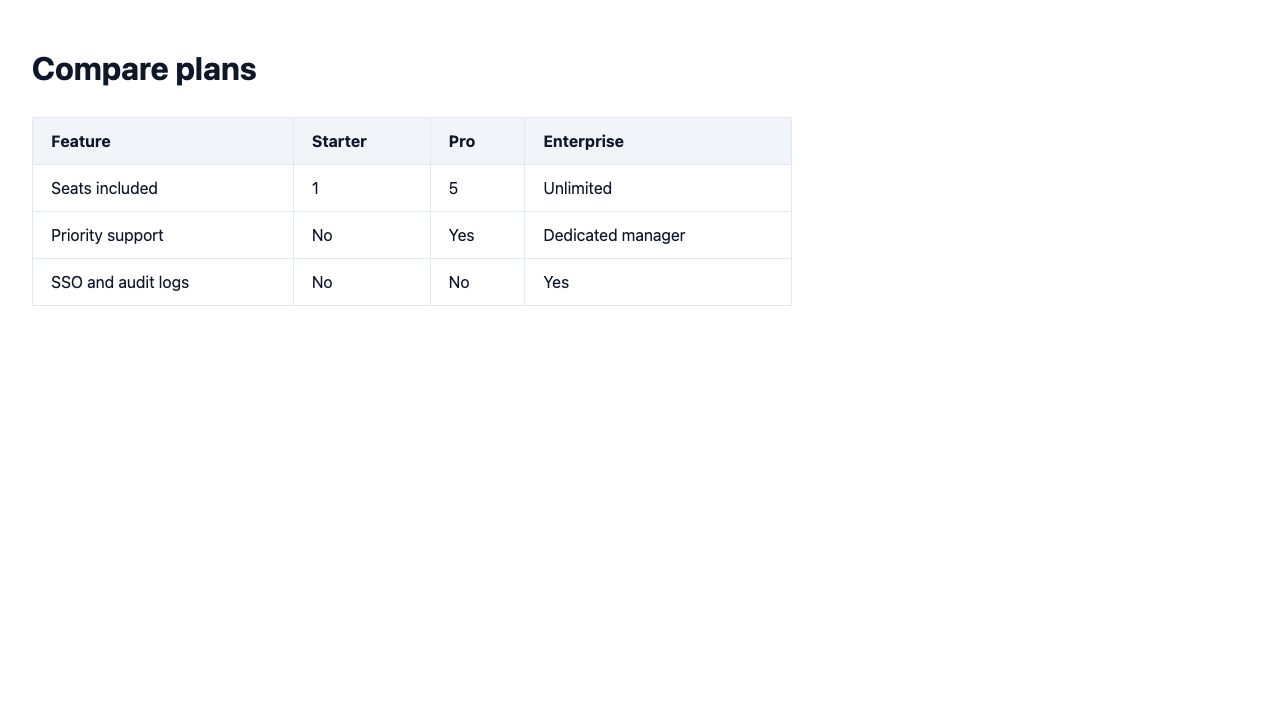
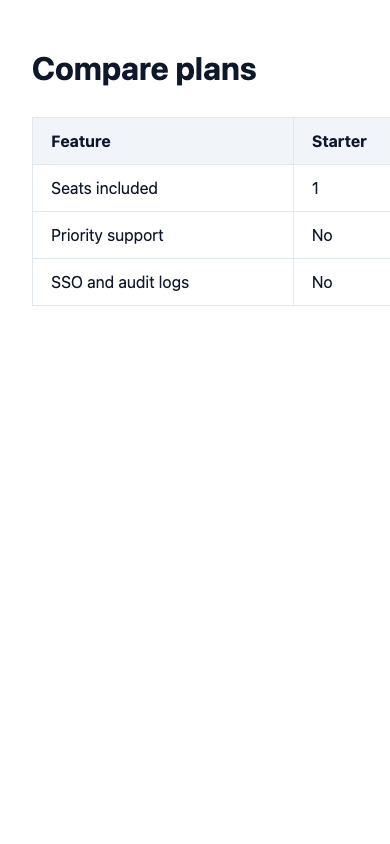
The vision model described the desktop as four columns and the mobile as two. The judge did the rest: "FAIL. Mobile render shows only two columns instead of the required four." The console error got caught the same pass. Measured before and after on the same pages: the old check caught zero of three defects, the new one caught all three. Same eight seconds of runtime.
Test 3: which model should write the code
I benchmarked two candidates for the coder job, head to head, with the generated code actually executed against test cases. Not vibes. Pass or fail on whether the code ran.
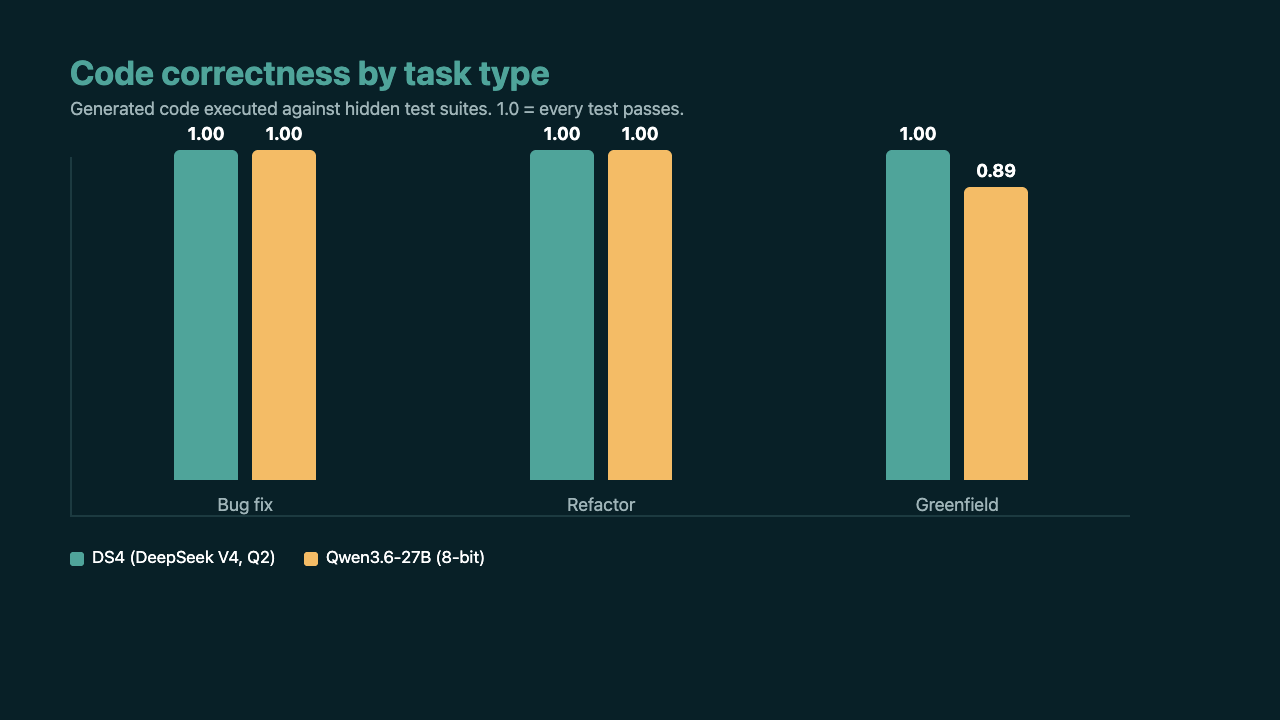
They tie on editing existing code. Both nail bug fixes and refactors. The interesting gap is cost. In an agentic loop, the model fires dozens of tool calls per task, and DeepSeek was about twice as fast and used a fraction of the tokens to get there.
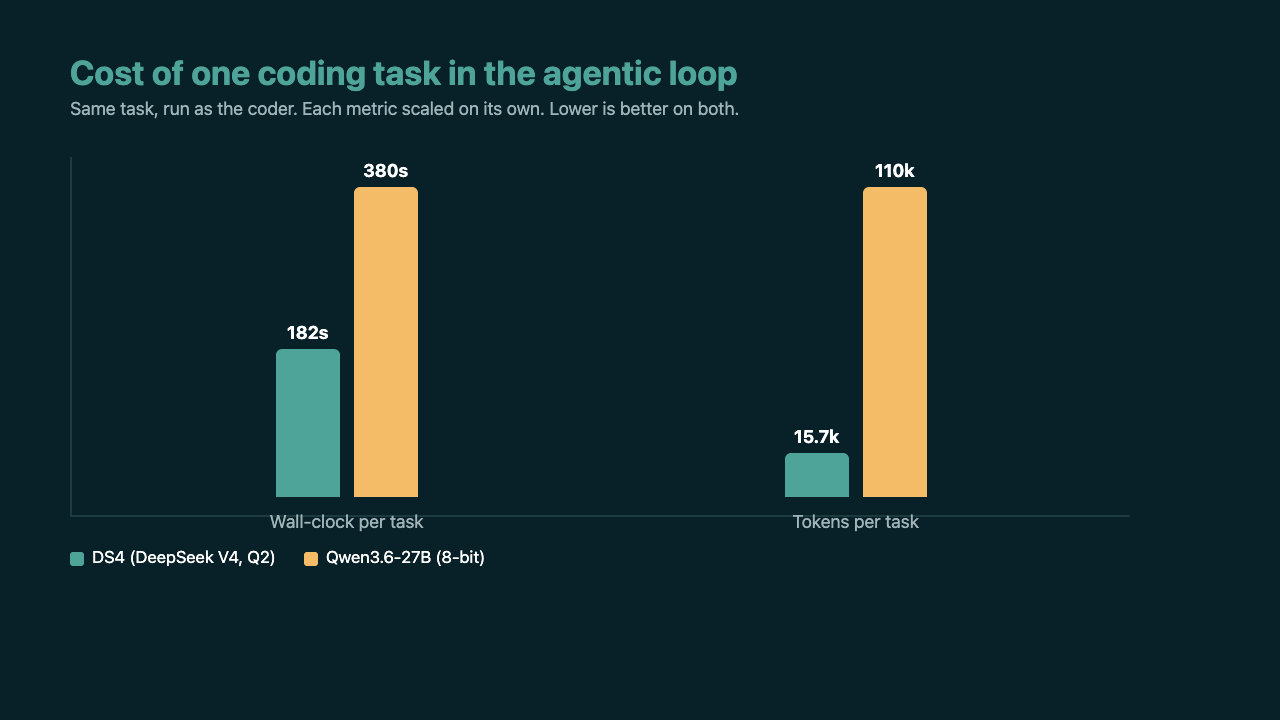
There was also a hard physical limit I learned the loud way. The coder takes 81GB of memory. The big vision model takes 29GB. Ask a 96GB machine to hold both and it does not decline politely. It swaps to disk, crawls, and locks the screen until I kill something over SSH. The 3GB vision model fits beside the coder with room left over. Small was not a compromise. It was the only thing that fit.
Test 4: when the measurement breaks before the model does
Here is the part most benchmark posts leave out. My measurements were wrong twice, in opposite directions, and both were the same kind of mistake.
First, DeepSeek looked weak at writing brand-new code from a blank file. It scored zero on one greenfield problem. The reason had nothing to do with its ability. It is a reasoning model that thinks out loud before writing, and my token cap was so low that it spent the entire budget thinking and never reached the code. Raise the cap and the score jumps from 0.00 to 1.00 on the exact same problem.
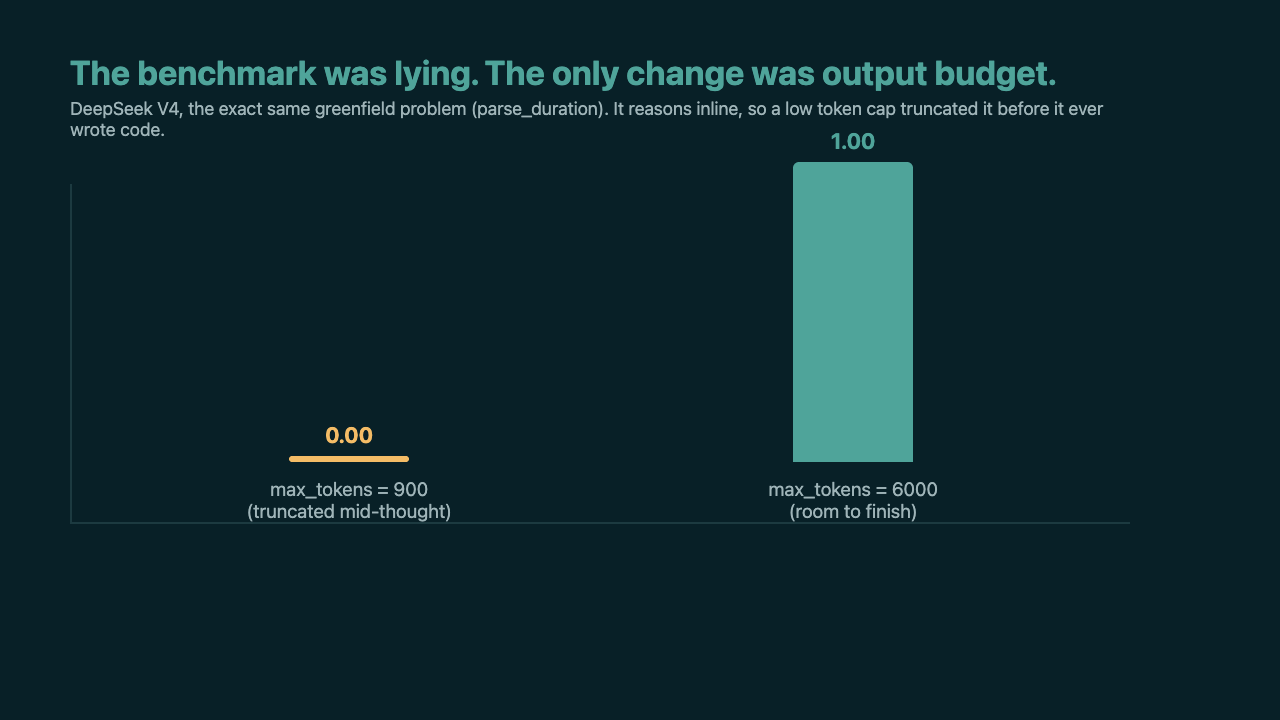
Then I ran the same test on the Qwen model and it scored zero on that problem too. Different reason, same shape: Qwen is slower, and my request timeout was short enough that it ran out of time mid-answer. One fixed limit starved the fast model on tokens. A different fixed limit starved the slow model on time.
The lesson is uncomfortable: "same harness for both models" is not the same as "fair." A fixed limit interacts differently with each model's speed and reasoning style. Once I set both generously, the real greenfield numbers came out clean: DeepSeek 1.00, Qwen 0.89. The bigger model was actually the less consistent one.
I also tested whether handing the coder example tests up front made it write better code. On these tasks, no measurable difference for either model. They were already good enough that the scaffolding had nothing to fix. So I am not building that feature. The benchmark talked me out of it, which is the whole point of running one.
I did not build this alone
I should be straight about how this got made, because the honest version is the better story. I did not write most of this code. Claude Code did. I set the direction, picked which models to put on trial, and overrode it when its read was off. It built the harnesses, ran the benchmarks, and debugged the screenshot pipeline.
We argued the whole way. I caught it treating two different things as the same because they shared a name. It caught me signing off on a result that turned out to be a screenshot of a blank page, which is the exact reason we found the approval-bias problem at all. The answer landed better than either of us would have reached alone.
What I actually believe now
The instinct with local AI is to grab the biggest model that fits and let it do everything. I think that is backwards. The setup that worked is a strong generalist doing the thinking, with a small specialist kept on a tight leash, doing the one narrow thing it is genuinely good at and nowhere near a decision it would fumble. The vision model only describes what it sees. The coder writes the code. The judge never has to look at a pixel.
And measure twice, because the test can fail before the model does. The trick was never finding a smarter model. It was giving each part a job small enough that it could not lie to me about it.