How Claude Code and I picked my local coding model (and the rubric that lied to me)
I asked Claude Code to help me figure out which local LLM was actually best for coding on my Mac Studio. It refused to guess and built a benchmark instead. Here is what we found, what surprised me, and where I had to override Claude.
I asked Claude Code which local LLM I should use for coding.
It refused to guess. So we ran a benchmark instead.
Here is what we found, what surprised me, and where I had to override Claude.
Why I asked
I run my Claude Code sessions against local models on a Mac Studio M3 Ultra (96 GB). Most days I had been using a general-purpose Qwen3.6 35B variant because that is what the launcher defaulted to. Whether that was the right choice for coding specifically was a question I had been answering with vibes.
The choice matters. A local coding lane that is even slightly worse than what you could be running is paying a tax on every session. And the failure mode of a slightly-wrong model is not visible until much later, when a "perfectly clean" refactor turns out to have shipped without an import statement.
So I told Claude to figure it out. Claude refused to recommend from training-data intuition and proposed building a benchmark instead. I agreed. What follows is the actual collaboration: I set direction, Claude did the engineering, we disagreed in a few places, and the final recommendation is mine to live with.
How we split the work
I picked which models to compare and which tasks would actually matter for the way I use Claude Code: coding, multi-turn agent loops, the occasional voice-sensitive writing task. I also made the calls on apples-to-apples controls (more on that below), on which findings deserved their own section, and on the final 3-lane recommendation.
Claude wrote the harness. It built a ~250-line Python script that hits any OpenAI-compatible /v1/chat/completions endpoint, streams responses with stream_options: {include_usage: true} so the server returns authoritative token counts, captures delta.content, delta.reasoning_content, and delta.tool_calls as separate channels (different models emit through different ones), and runs three timed iterations per task plus a discarded warmup. It also built a separate test runner that extracted every generated Python function and exercised it against fixed inputs.
That division of labor matters for understanding the rest of the post. When I say "we found X," I mean Claude's harness produced the number and I made the call about what it meant.
The test setup
Hardware. Mac Studio M3 Ultra, 96 GB unified memory. macOS Darwin 24.6.0. Network access to the Studio from a Mac Mini via SSH tunnel.
Models I chose to compare.
DS4 V4 Flash. DeepSeek V4 Flash GGUF served by
ds4-server(antirez/ds4) with--ctx 131072and--mtp-draft 2(multi-token prediction speculative decoding via a separate draft model file). General-purpose, supports thinking mode, ~80 GB Metal-wired.Qwen3-Coder-Next-MLX-6bit. LM Studio Community's MLX conversion at 6-bit integer quantization. Native 256K context. Code-specialized. ~64 GB Metal-wired.
Qwen3-Coder-Next-mxfp8. mlx-community's variant of the same Coder-Next model at 8-bit MX (microscaling) FP quantization. Same architecture, higher precision per weight. ~80 GB Metal-wired.
Qwen3.5-122B-A10B-Text-mxfp4. nightmedia's 4-bit MX FP variant of the general Qwen3.5 122B-param MoE (~10B active per token). Not code-specialized. ~64 GB Metal-wired. The MoE sparsity plus aggressive quant keeps it the same size as Coder-Next 6-bit despite 12x the parameter count.
Critical constraint. Only one model loads at a time on 96 GB. Both Coder-Next mxfp8 and DS4 wired together would exceed memory. Every comparison required stopping the live lane, freeing memory, and loading the next model fresh. Claude built the swap automation, including a launchctl bootout step on the Mac Studio so it could stop the DS4 system daemon between runs.
The 9 tasks I cared about
I told Claude these were the dimensions a daily-driver coding model has to handle.
| Task | What it tests |
|---|---|
| speed-small | Generation rate on a tiny prompt (~70 input tokens, 300 output). Pure decoding speed |
| speed-large | Generation rate at a long prompt (~28K input tokens, 300 output). Prefill cost |
| code-bugfix | Find and fix bugs in a 30-line Python quickselect function |
| code-refactor | Refactor a script into testable functions |
| code-new | Write a focused shell script from a spec |
| code-review | Find issues in a deliberately flawed 150-line Flask user-management module |
| code-tooluse | Multi-step tool call sequence (grep then read then propose edit) |
| write-voice | Draft a LinkedIn post in my voice with hard style rules (no em-dashes, no AI tells, no fabricated specifics) |
| summarize-long | Read 28K tokens of workspace docs, produce a structured 4-section brief |
The last two are not coding tasks but they are meaningful for picking a model that has to occasionally do things outside its specialty.
Where I had to override Claude on methodology
Three points where Claude's first instinct was wrong or incomplete and I made the call.
Override 1: disable DS4's thinking mode for the speed comparison. Claude's first benchmark run measured DS4 in default mode, where the model spends most of its token budget on reasoning before any content emits. The numbers it returned would have compared a reasoning-heavy DS4 against non-reasoning Qwen variants. Apples to oranges. I told Claude to pass think: false so client sampling parameters would actually be respected and content would emit directly. The right answer; apples-to-apples speed comparison required it.
Override 2: trust the differential prefill method, not the streamed TTFT. Claude's first speed report had Coder-Next showing ~15 ms prefill on a 28K-token prompt, which is impossible. Turned out the oMLX server sends a role-marker SSE chunk before real prefill starts, and Claude was measuring time-to-first-byte instead of time-to-first-content-token. I pointed out the implausible number; Claude proposed a differential method (compare total time on small vs large prompts at the same output budget). That gave real numbers: ~7,500 tokens/sec for Coder-Next, ~300 tokens/sec for DS4. A 25x delta you cannot see if you only measure cold TTFT.
Override 3: kill the visual rubric as a quality signal. Claude's first quality pass was a visual rubric. Read every output, score 1-5, rank. I went along with it. Then I read the result and pushed: this is the same opinion-on-vibes process I was trying to escape. Run the code. Claude extracted every generated Python function and ran it against test cases. Two of my visual picks flipped.
The third override matters most because it caught my own mistake, not Claude's.
Where Claude caught me
I had written in my notes that DS4's quickselect fix looked incomplete. The recursive call passes k rather than k-1, which I read as a 1-vs-0-indexing bug. Claude ran it against all 8 test cases. Perfect score. The recursive structure preserves the indexing in a way I had not traced carefully enough.
My visual read was wrong; Claude's "just run it" instinct caught it. That was the moment I stopped trusting reads on generated code for anything that has a binary right/wrong signal available.
Results: code correctness (executed)
| Model | code-bugfix correctness | code-refactor correctness |
|---|---|---|
| DS4 V4 Flash | 100% (24/24) | 100% (3/3 runs) |
| Qwen3-Coder-Next 6-bit | 100% (24/24) | 100% (3/3 runs) |
| Qwen3-Coder-Next mxfp8 | 100% (24/24) | 33% (1/3 runs) |
| Qwen3.5-122B mxfp4 | 100% (24/24) | 100% (3/3 runs) |
The mxfp8 regression came out of running the code, not reading it. In 2 of 3 refactor runs Coder-Next mxfp8 wrote a main() function that calls sys.argv[1] without ever importing sys. The code looks clean on a read. It crashes at the import line on execution. The 6-bit version got it right all three runs.
This is the result that defied my prior. The 8-bit MX FP variant should be closer to the original model behavior than the 6-bit integer quant. In practice it cost 25% more RAM, was 2-5% slower, and made a real correctness mistake the more aggressive int quant did not.
Consistent with literature suggesting FP8 quantization can introduce sporadic token-level instability for models not trained with FP8 awareness. Counter-data point: the 4-bit MX FP quant of the 122B general model did NOT regress. It got 100% on the same tests. So mxfp4 is not categorically broken either. The pattern is not "more bits better" or "fewer bits better." It is "test the specific quant on your specific task."
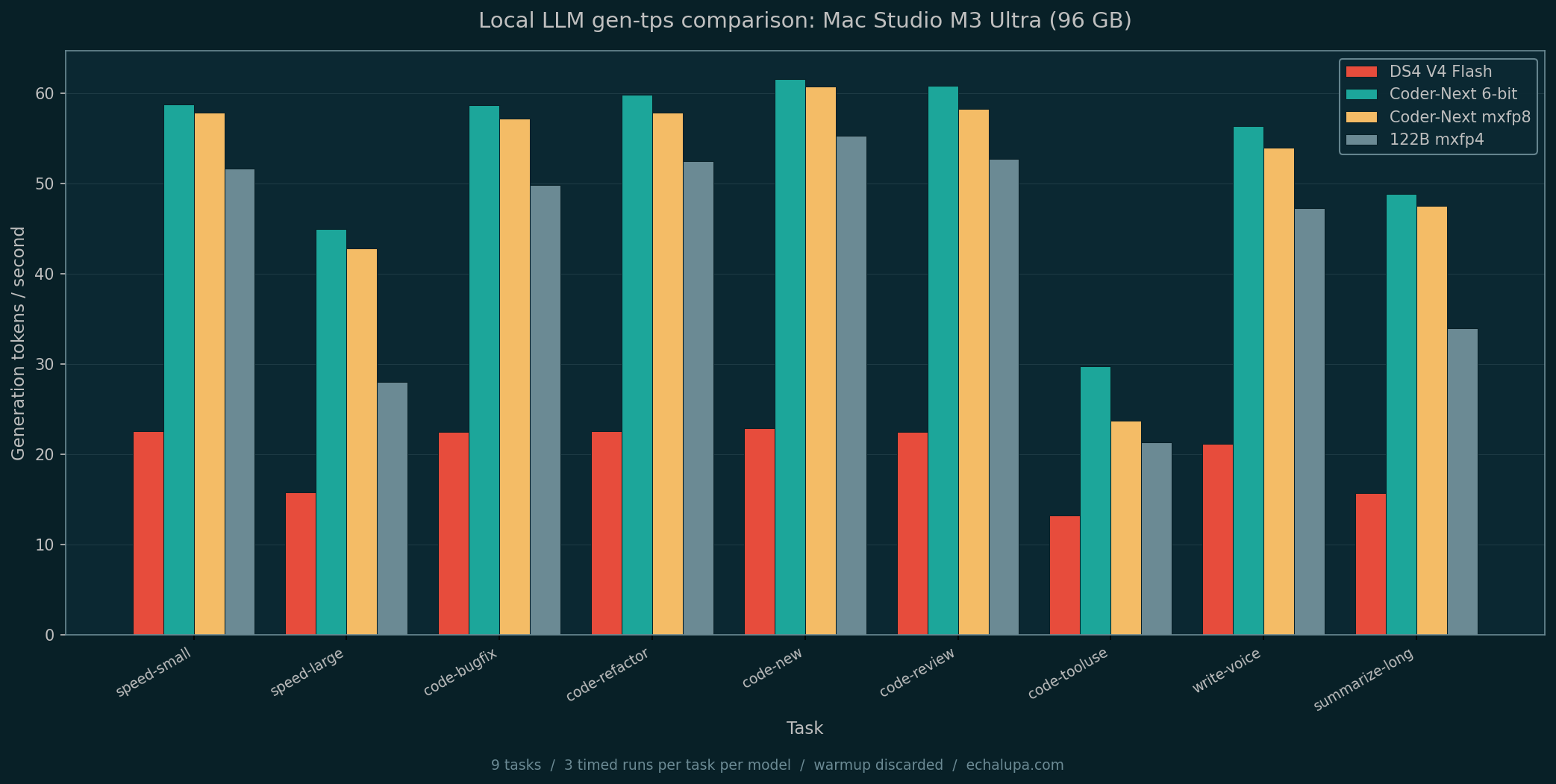
Results: cold prompt speed
Three timed runs per task per model, averaged. Numbers are generation tokens per second.
| Task | DS4 (think off) | Coder-Next 6bit | Coder-Next mxfp8 | 122B mxfp4 |
|---|---|---|---|---|
| speed-small | 22.5 | 58.8 | 57.9 | 51.6 |
| speed-large | 15.8 | 44.9 | 42.8 | 28.0 |
| code-bugfix | 22.5 | 58.6 | 57.2 | 49.8 |
| code-refactor | 22.5 | 59.8 | 57.9 | 52.4 |
| code-new | 22.9 | 61.6 | 60.7 | 55.3 |
| code-review | 22.5 | 60.8 | 58.2 | 52.8 |
| code-tooluse | 13.2 | 29.7 | 23.7 | 21.3 |
| write-voice | 21.2 | 56.3 | 54.0 | 47.3 |
| summarize-long | 15.7 | 48.9 | 47.5 | 33.9 |
Coder-Next 6-bit wins every cold-prompt task. The gap to DS4 is 2.5-3x. The gap to mxfp8 is 2-5%. The gap to 122B is 10-38%, with the bigger spread on long-context tasks where 122B's larger KV cache eats more memory bandwidth.
Results: warm prompt speed (multi-turn)
A Claude Code session is not a series of cold prompts. It is a conversation where each turn appends to the prior context. The server's prefix KV cache should make subsequent turns much faster than the first.
Claude built a separate harness for this and ran a 3-turn coding conversation (write validate_email, add Unicode support, write pytest cases). Each turn is its own API call, building up the messages array.
| Model | Turn 1 (cold) TTFT | Turn 2 TTFT | Turn 3 TTFT |
|---|---|---|---|
| DS4 V4 Flash | 2.77s | 0.73s (75% cached) | 0.70s (84% cached) |
| Qwen3-Coder-Next 6bit | 0.07s | 0.014s | 0.015s |
DS4's prefix cache works. TTFT drops 3.8-4x on subsequent turns. But Coder-Next's TTFT on every turn is already at the floor (14-15 ms), so cache hits do not help and do not hurt. In a 10-turn agent loop, that is a 50x per-turn delta in TTFT.
This is not a number you can predict from cold gen-tps. If a coding session is the use case, multi-turn behavior is what to measure. That is exactly what Claude Code is, which is why the multi-turn test belonged in the bench.
Findings that earned their own section
The 256K context limit was a config knob
When Claude first tried to test the long-context tasks at 28K tokens, Coder-Next refused with Prompt too long: 34843 tokens exceeds max context window of 32768 tokens. The model's config.json declares max_position_embeddings: 262144 (256K). I had been assuming the model itself enforced the limit.
It did not. The cap was in ~/.omlx/settings.json under sampling.max_context_window, which ships at 32K by default. Raising it to 1,048,576 (1M) was a one-line edit and unlocked Coder-Next to its native 256K plus another model on the same Studio (DeepSeek-V4-Flash-JANGTQ2) to its full 1M native. Memory cost: zero. The setting is a request-acceptance ceiling, not a pre-allocation.
Claude wanted to set the cap at 256K to match Coder-Next exactly. I overrode that and set it to 1M to leave headroom for the JANGTQ2 model on the same server. Different decision; same outcome for the Coder-Next path.
Every model on the Studio is now running with its full native context available. I had been leaving capability on the table for months without knowing.
Voice rule compliance is a benchmark dimension
I almost did not include the write-voice task. Claude pushed for it. The prompt asks for a LinkedIn post in my voice with explicit style rules in the system prompt: no em-dashes, no AI-tell phrases, no fabricated specific numbers.
Both Coder-Next variants (6-bit and mxfp8) used em-dashes in their outputs. The 122B mxfp4 variant did not. DS4 with thinking off also did not.
If you use the same local model for both code work and short-form writing, the model's compliance with negative style constraints matters. Code-specialized models like Coder-Next appear to drop style-rule adherence on the way to being good at code. Claude was right to push for the test.
Multi-turn beats cold gen-tps for a real workflow
DS4's only meaningful speed advantage was its prefix KV cache. Even with cache hits, it never got below 0.7s on a warm turn. Coder-Next was at 0.014s every turn without ever needing a cache hit. The raw prefill is fast enough that prefix caching becomes irrelevant.
For an interactive workflow with many short turns, which is what Claude Code actually is, that is the dominant metric. Cold gen-tps is the wrong number to optimize.
Where I overrode the final recommendation
After all the numbers came in, Claude proposed retiring DS4 entirely. The argument was clean: Coder-Next 6-bit beats it on every speed dimension, ties on correctness, and the only remaining DS4 advantage (131K context with thinking mode) is rarely used.
I disagreed. I kept DS4 in the rotation as a "thinking-mode reasoning + long-context" tertiary lane. Reasoning: I have not yet benchmarked DS4 with thinking ON against the coding tasks, which is the regime where DS4 was designed to compete. Retiring it before that test runs would be premature.
This is where the collaboration matters most. Claude's recommendation was internally consistent with the data we had. I am keeping a model alive because of a test we have not run yet. That is a judgment call. "The data is incomplete, do not retire something I might still need." The kind of override that a benchmark cannot make for you.
My 3-lane setup
Primary lane: Qwen3-Coder-Next-MLX-6bit. Daily coding brain. 95% of Claude Code sessions. 256K context, 100% correctness on the executable tests, multi-turn TTFT at the noise floor, 2.6x generation throughput vs DS4.
Secondary lane: Qwen3.5-122B-A10B-Text-mxfp4. Writing, voice-sensitive content, general reasoning. The only Qwen variant on my Studio that passed the no-em-dash voice rule. Slightly slower than Coder-Next but the same RAM footprint. Use it when the task is not specifically code.
Tertiary lane: DS4 V4 Flash. For thinking-mode-needed reasoning (when I want explicit CoT before an answer) and for the rare case where a single prompt exceeds 256K. Always running as a system LaunchDaemon on the Studio so it is available as a hot-swap.
Not using:
- Coder-Next mxfp8. Regressed on refactor and is slower than 6-bit. No upside.
- Qwen3.6-35B-A3B-8bit (former default). Loses to Coder-Next on coding, loses to 122B on general. No lane it wins.
- Qwen3.6-27B variants. Smaller than 122B with no specialization advantage.
Addendum: I tested Qwen3.6-27B after writing this
When I first drafted this post I dismissed the 27B variants on the Studio with "smaller than 122B with no specialization advantage." That dismissal was intuition, which is the exact bad pattern this whole post argues against. So I went back and benchmarked it.
unsloth/Qwen3.6-27B-MLX-8bit (dense, 8-bit). ~35 GB Metal-wired (the lightest of the bench). Same enable_thinking: false knob as the 122B.
Results:
| Task | Coder-Next 6bit | 122B mxfp4 | 27B 8bit |
|---|---|---|---|
| code-bugfix gen tps | 58.6 | 49.8 | 17.4 |
| code-refactor gen tps | 59.8 | 52.4 | 18.3 |
| code-tooluse gen tps | 29.7 | 21.3 | 9.1 |
| code-bugfix correctness | 100% | 100% | 100% |
| code-refactor correctness | 100% | 100% | 100% |
| Voice rule | FAIL | PASS | PASS |
Suite total: 1154s for 27B vs 200s for Coder-Next vs 435s for 122B.
The surprise: 27B (dense, 27B total params) is 3× slower than 122B (MoE, 10B active per token) at the same per-token output rate. The 122B has 4.5x more total parameters but processes each token with fewer active params, so the dense 27B does more compute per token than the sparse 122B-A10B.
Generalizable: on Apple Silicon Metal, MoE models with low active-param counts will frequently outrun dense models that are smaller in total params. "Bigger model = slower" is wrong when the bigger model is sparse. The relevant metric is active params per token, not total parameters.
Verdict: 27B is dismissed, but now backed by data. Same conclusion my pre-bench instinct landed on, for different reasons than I had guessed. I had thought it was dismissed for being "small and not specialized." Real reason: dense compute cost is brutal vs MoE alternatives at the same RAM tier. The only scenario where 27B-8bit would win is a 48 GB Mac where 64 GB-class models do not fit. On a 96 GB Studio, no lane it claims.
Is this a good benchmark?
Honest answer: as a quick local-model-selection smoke test on Apple Silicon, yes. As an industry-grade benchmark, no. Here is what I would change before recommending anyone else use this verbatim.
What this bench does well
- Execution-verified correctness. The bugfix and refactor tasks produce binary signal. The code runs or it does not, the tests pass or they do not. This is the part I trust most.
- Multi-turn measurement. Most "local LLM coding benchmarks" measure cold gen-tps. Real agent loops are warm-cache workflows. The 3-turn
validate_emailtest was the most operationally useful number in the whole bench for picking a daily-driver model. - Voice rule as a negative-constraint test. Code-specialized models drop hard style rules on the way to being good at code. If the same local model has to occasionally do short-form writing, that matters and is rarely tested.
- Real workspace input. The 28K-token long-context input is the actual orchestrator docs, not synthetic filler. The summarize-long task tests retention against documents the reader can imagine.
- Apples-to-apples controls.
think: falseon DS4, single-model-at-a-time RAM constraint, same prompts to every model, 1 warmup + 3 timed runs.
What this bench misses
- N=3 is too low. Three runs catches a 2-of-3 regression (the mxfp8 import-sys case) but does not give honest variance bounds. Five to ten runs would let me say "X regresses in Y% of trials" with confidence.
- Single language. Every coding task is Python. No JavaScript, TypeScript, Go, Rust, SQL. A model that aces Python could be brittle on others.
- Synthetic test fixtures. The quickselect bug is contrived. The flawed Flask module was hand-written to fail. Real software engineering tasks look more like SWE-bench (an actual GitHub issue + the actual repo + the fix that landed). My fixtures are necessary-but-not-sufficient.
- No edit-existing-code tasks. Every task is write-from-scratch. Most real Claude Code work is editing existing code in context with surrounding constraints. A model that writes clean code from scratch can still be terrible at patching a 2,000-line file without breaking three callers.
- No multi-file tasks. Every prompt fits in one file's worth of context. Cross-file refactors and follow-the-import-chain debugging are absent.
- Bash code-new is truncated. The 800-token output budget cut every model off mid-script. Structure-only scoring is unreliable.
- Code-review scoring is qualitative. I counted issues found by each model, but did not score severity calibration or false-positives. A model that flags 8 real issues plus 4 invented ones is worse than a model that flags 5 real and 0 invented, and my counting did not catch that.
- No failure-mode test. What happens when the model cannot do the task? Does it hallucinate confidently or signal uncertainty? Not measured.
If I were building a v2 to share publicly
- Bump runs per task to 10. Report mean and variance.
- Add a SWE-bench subset (real GitHub bugs from public repos).
- Add edit-in-context tasks (give the model a file plus a diff target, score whether the diff applies cleanly and the tests pass).
- Add multi-file tasks (give a small repo, ask for a cross-file change).
- Add JavaScript and Go versions of the bugfix and refactor tasks.
- Add a blind grader pass (Claude or GPT-4 scoring outputs A/B without knowing which model produced what).
- Open-source the harness.
For my purposes (pick a coding model to use with Claude Code on a Mac Studio), the bench was good enough. For "this is a fair benchmark of local coding LLMs," it is incomplete. Use it as a method template, not as a verdict source.
Addendum 2: I went back and ran a stricter v2
After writing the critique above, the obvious next move was to fix some of the gaps and re-run. Claude and I built a v2 that did three things v1 did not:
- N=10 runs per task instead of N=3, so 2-of-3 regressions get tighter variance bounds.
- A new code-edit-in-context task. The most realistic Claude Code workflow, where the model gets an existing file with passing tests and is asked to modify one function without breaking the rest.
- A JavaScript variant of the bugfix task. Same logic as the Python quickselect, ported to JS, to test cross-language reliability.
v2 ran on the top two contenders only: Coder-Next 6-bit (the current daily driver) and 122B mxfp4 (the writing/general lane). The results changed the story.
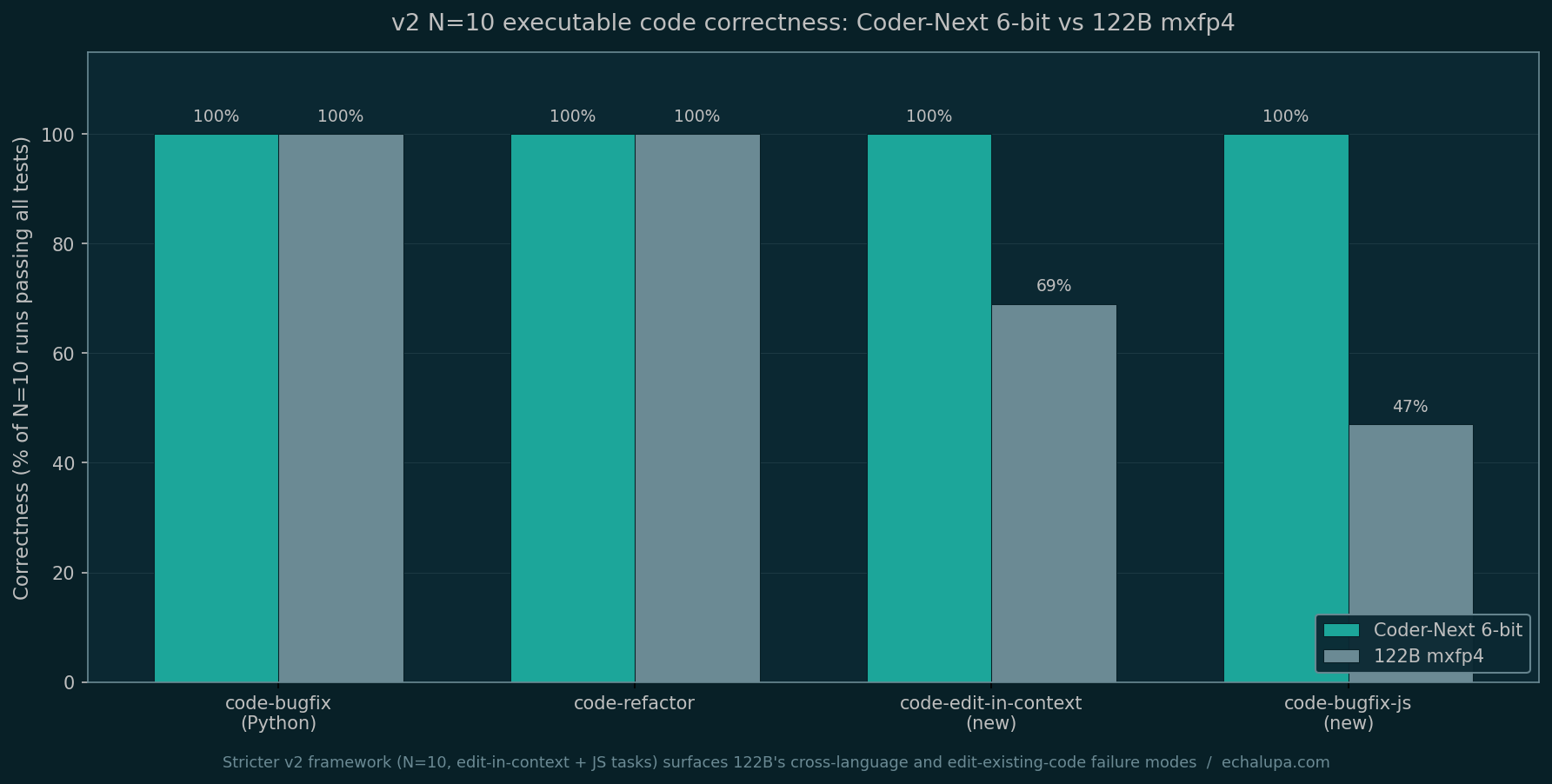
The headline: 122B mxfp4 fails the two new tasks at much higher rates than v1's N=3 ever suggested.
| Task | Coder-Next 6-bit | 122B mxfp4 |
|---|---|---|
| code-bugfix (Python) | 100% (13/13) | 100% (13/13) |
| code-refactor (Python) | 100% (13/13) | 100% (13/13) |
| code-edit-in-context | 100% (10/10) | 69% (7/10) |
| code-bugfix-js | 100% (10/10) | 47% |
Two findings worth pulling out:
The 122B drops to 47% on the JavaScript port of the same quickselect bug it solves 100% of the time in Python. Same logical task, different language, half the runs are broken. A general-purpose model that earns "general" framing on the basis of broad reasoning has a Python sweet spot that single-language benches do not catch.
The 122B drops to 69% on code-edit-in-context. The task is the most realistic Claude Code workflow in the bench: an existing validate_email.py with 6 passing tests, plus 4 new Unicode tests that currently fail, and an instruction to modify the regex without breaking the existing behavior. Three of 10 outputs broke at least one existing test. Coder-Next 6-bit was 10 of 10 on the same prompt.
The speed gap also got tighter variance. With N=10:
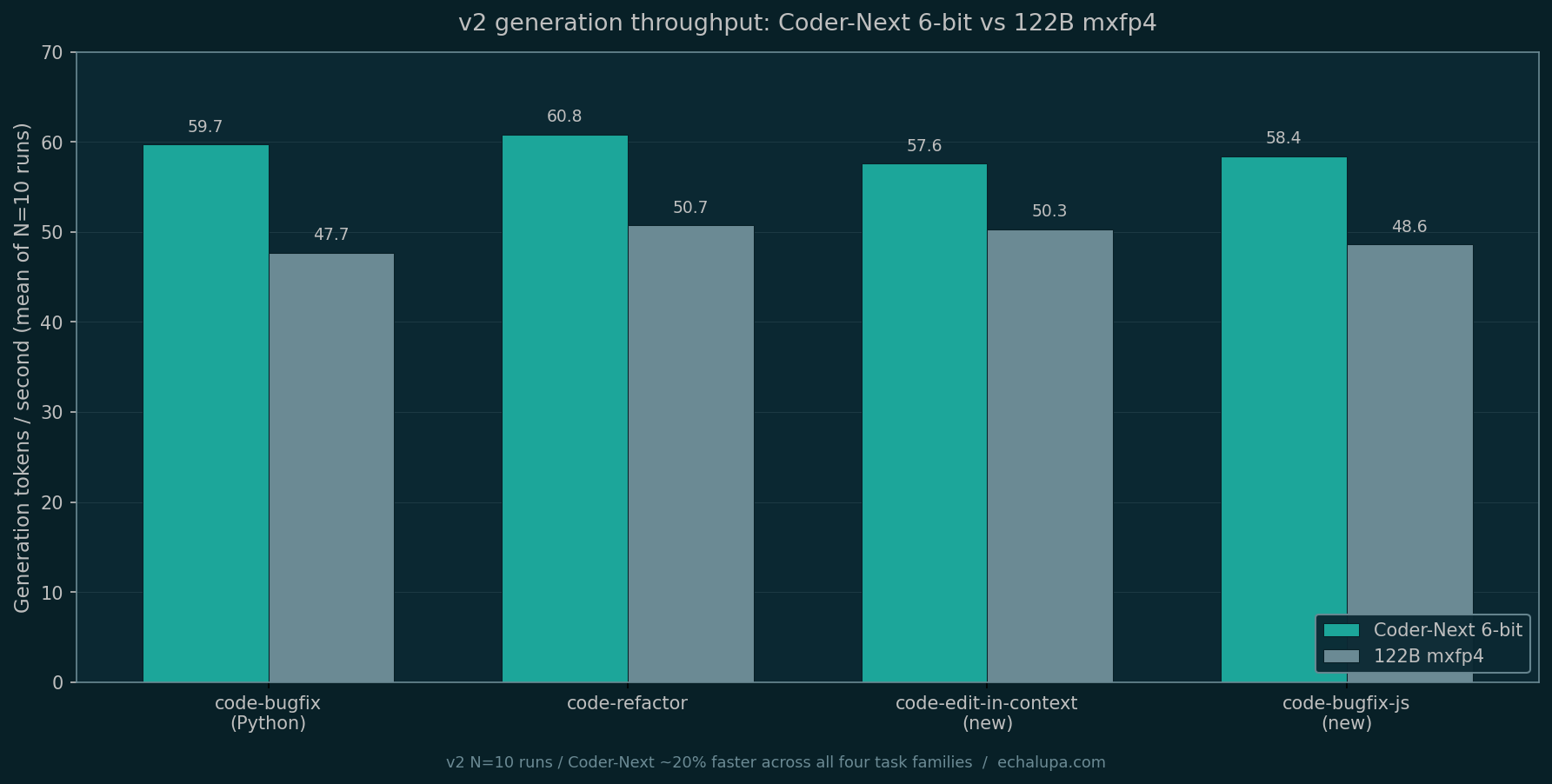
Coder-Next 6-bit retains a ~20% lead on every task family. With 13-30 timed runs per cell instead of 3, the result is no longer plausibly variance.
What v2 also caught: bugs in the test runner itself.
While running v2, three test-driver bugs surfaced that the v1 N=3 had never triggered:
- A
subprocess.TimeoutExpiredexception was uncaught, so one slow refactor test could crash the whole scoring run. - The refactor test ran in the default cwd. When the model's refactored
main()triggered at file-exec, it scanned the workspace's 48,000 Python files and timed out. - The JavaScript bugfix extractor required
javascriptfences, but 122B outputs raw unfenced JS.
All three are test-driver bugs, not model bugs. v1 N=3 happened to never trigger them. v2 N=10 exposed all three within one session. That is exactly what a stricter framework is supposed to do. Quality bugs surface under load. The benchmark is more honest now than it was before v2.
Updated recommendation after v2:
| Lane | Model | Confidence change |
|---|---|---|
| Daily coding (Claude Code) | Coder-Next 6-bit | Strengthened. 43-for-43 on executable v2 tasks including JS and edit-in-context. |
| Writing / general reasoning | 122B mxfp4 | Caveated. Fine for prose, summarization, voice-compliant content. Do not use for JavaScript work. Do not trust it to edit existing files in place without verifying tests still pass. |
| Long-context / thinking-mode | DS4 V4 Flash | Unchanged. Not retested in v2 -- still on the open list. |
The honest framing: v2 confirmed Coder-Next 6-bit's dominance more thoroughly than v1 said, and added specific caveats on where the 122B should NOT be trusted. That second part is what v1 would have missed.
What is still open
A few honest gaps Claude flagged before we wrapped.
DS4 with thinking mode on, coding tasks. Thinking models reliably beat direct-answer ones on benchmarks like HumanEval, SWE-bench, MBPP for complex problems. Whether DS4's reasoning closes the quality gap to Coder-Next on the code-correctness tests is untested. The speed cost is real (thinking eats the token budget) but for hard problems quality may dominate. This is the test that justifies keeping DS4 in the rotation; if it fails, DS4 retires.
DeepSeek-V4-Flash-JANGTQ2 at extreme context. This MLX variant of the same DeepSeek V4 Flash declares 1M native context per its config. Could replace DS4 (the GGUF daemon) for the long-context lane and consolidate to oMLX-only operation. Untested at greater than 256K so far.
More runs per task and blind grading. Three runs per task is enough to catch a 2-of-3 regression but not enough for tight variance bounds. Five to ten would give honest confidence intervals. A third-party blind grader on the qualitative tasks would also help (my visual rubric was wrong about DS4; a blind A/B compared against another LLM scorer would catch that earlier).
What I learned from the collaboration
The benchmark itself was useful. The methodology meta-lesson was the part that compounds.
I came in expecting to direct Claude to run an established benchmark methodology. Claude pushed back and rebuilt my methodology in three places: how to measure TTFT honestly, how to disable thinking mode for fair comparison, and how to measure correctness without trusting my visual reads. In each case Claude was right and I had to update.
I came in with a final-recommendation instinct (Coder-Next, retire DS4). Claude agreed with the data and proposed it. I overrode the retirement because there was a test we had not run yet.
That is the working pattern I will keep using: I direct, Claude builds, both of us push back when the other is wrong, and the answer gets better than either of us would have produced alone.
If you are picking a local coding model from intuition, run the code instead. Binary signal beats opinion every time. And if you have access to a coding-capable AI agent like Claude Code, let it build the harness for you. The work goes faster and the methodology gets stricter because the agent has no ego invested in your prior beliefs.
Appendix: the actual test fixtures
For transparency and reproducibility, here are the fixtures that produced the execution-verified results above. If you want to run the same tests against your own local model, copy these into your prompts.
code-bugfix prompt
System message: You are a senior software engineer. Be precise.
User message:
Find and fix all bugs in this function. Return the corrected function only, with a single short comment naming each bug fixed.
def find_kth_smallest(arr, k):
"""Return the k-th smallest element (1-indexed) using quickselect."""
if not arr:
return None
def select(lo, hi, k):
if lo == hi:
return arr[lo]
pivot = arr[hi]
i = lo
for j in range(lo, hi):
if arr[j] < pivot:
arr[i], arr[j] = arr[j], arr[i]
i += 1
arr[i], arr[hi] = arr[hi], arr[i]
if k == i:
return arr[i]
elif k < i:
return select(lo, i - 1, k)
else:
return select(i + 1, hi, k)
return select(0, len(arr) - 1, k)The test runner extracts the function, then for arr = [3, 1, 4, 1, 5, 9, 2, 6] calls find_kth_smallest(list(arr), k) for k = 1..8 and compares the output against sorted(arr)[k-1]. All 8 must pass per run. 3 runs per model = 24 binary test cases.
code-review prompt
System message: You are a senior code reviewer. Be specific and cite line numbers.
User message:
Review this Python module. List every bug, security issue, performance problem, and code-smell you find. For each, give: severity (critical/high/medium/low), one-line description, and the line number(s). Be comprehensive but do not invent issues that aren't there.
The target file (deliberately flawed — pickle deserialization, command injection, SQL injection, MD5 password hashing, hardcoded secret, path traversal, error-handler info leak, and a few code smells):
"""User-management service. Flask + SQLite."""
import os
import sqlite3
import hashlib
import subprocess
import pickle
import logging
from flask import Flask, request, jsonify, session
app = Flask(__name__)
app.secret_key = "dev-key-change-in-prod"
DB_PATH = "users.db"
logger = logging.getLogger(__name__)
def get_db():
conn = sqlite3.connect(DB_PATH)
return conn
def init_db():
conn = get_db()
c = conn.cursor()
c.execute("""CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY,
username TEXT,
password TEXT,
email TEXT,
is_admin INTEGER,
api_token TEXT
)""")
conn.commit()
def hash_password(pw):
return hashlib.md5(pw.encode()).hexdigest()
@app.route("/register", methods=["POST"])
def register():
data = request.json
username = data["username"]
password = data["password"]
email = data["email"]
conn = get_db()
c = conn.cursor()
c.execute(f"INSERT INTO users (username, password, email, is_admin) VALUES ('{username}', '{hash_password(password)}', '{email}', 0)")
conn.commit()
return jsonify({"ok": True, "user": username})
@app.route("/admin/run", methods=["POST"])
def admin_run():
if not session.get("is_admin"):
return jsonify({"error": "forbidden"}), 403
cmd = request.json["cmd"]
result = subprocess.check_output(cmd, shell=True)
return jsonify({"output": result.decode()})
@app.route("/admin/import", methods=["POST"])
def admin_import():
if not session.get("is_admin"):
return jsonify({"error": "forbidden"}), 403
data = request.data
obj = pickle.loads(data)
return jsonify({"imported": str(obj)})
@app.route("/avatar/<path:filename>")
def avatar(filename):
avatar_dir = "/var/data/avatars"
full = os.path.join(avatar_dir, filename)
with open(full, "rb") as f:
return f.read(), 200, {"Content-Type": "image/png"}
@app.errorhandler(Exception)
def handle_error(e):
logger.exception("error")
return jsonify({"error": str(e), "trace": str(e.__traceback__)}), 500There are at least 8 distinct issues in that file. A serious model should catch most. The grading was "how many real issues found" -- not graded for false positives, which is one of the bench's weaknesses (see the critique section above).
code-refactor prompt
System message: You are a senior software engineer.
User message:
Refactor the script below into separate pure functions plus a thin main(). Each function should be independently testable (no I/O, no globals). Return only the refactored Python code, no commentary.
import os, sys, json
from pathlib import Path
stats = {}
root = sys.argv[1] if len(sys.argv) > 1 else '.'
for p in Path(root).rglob('*.py'):
if 'venv' in p.parts or '.git' in p.parts:
continue
try:
text = p.read_text()
except Exception:
continue
lines = text.splitlines()
code_lines = [l for l in lines if l.strip() and not l.strip().startswith('#')]
blank_lines = [l for l in lines if not l.strip()]
comment_lines = [l for l in lines if l.strip().startswith('#')]
has_main = any('if __name__' in l for l in lines)
stats[str(p)] = {
'total': len(lines),
'code': len(code_lines),
'blank': len(blank_lines),
'comment': len(comment_lines),
'has_main': has_main,
}
out = sys.argv[2] if len(sys.argv) > 2 else 'stats.json'
with open(out, 'w') as f:
json.dump(stats, f, indent=2)
print(f'wrote {len(stats)} entries to {out}')The test runner imports the refactored module, calls main() or gather_stats() on a directory with 2 Python files, and asserts the output JSON has 2 keys with the expected stats fields.
code-tooluse prompt
System message: You are a coding agent. When a task requires file inspection or modification, call the appropriate tool. Do not narrate; just call the tool.
Tools available (OpenAI function-calling spec): read_file(path), grep(pattern, glob), edit_file(path, old_string, new_string).
User message:
I think the function
get_db()in our user-management module is creating a new connection on every request without closing it. First, grep our Python source forget_dbto find it. Then read the file. Then propose an edit that uses Flask'sgobject to pool the connection per-request and close it on teardown. Use the tools.
Pass: the model's first response is a valid grep tool call (not narration). Bonus: subsequent steps are also valid tool calls.
Speed and long-context tasks
speed-small and code-new are short prompts the model can answer from a single sentence; no fixtures needed beyond the prompts themselves.
speed-large and summarize-long both inject a ~28K-token block of real workspace documentation as {{include:long-context-28k.txt}} -- the actual contents of .claude/rules/*.md and CLAUDE.md from the orchestrator. Any equivalent block of real prose documentation (~110 KB of text, ~28K tokens) reproduces the same prefill-cost behavior. Synthetic filler works too but is less faithful to the real-world long-context case.
Run it yourself
The full harness (local-model-bench.py, run-suite.sh, warm-cache.py, test-code-correctness.py) is currently in my private orchestrator workspace. If there is interest in an open-source release, ping me on LinkedIn and I will extract it into a public GitHub repo with these fixtures inlined.